Overview
A node is a computer that is connected to a network. In our case, each node is running the Aion kernel. Each node talks to other nodes on the network to do things like run applications, or confirm transactions. Unlike other networks, we have implemented the Aion virtual machine (AVM) on both the Java and Rust kernels. Operationally both these kernels function the same way and react identically when queried by the network. The purpose of having two kernels is for redundancy. If one of the kernels is compromised, the other kernel is able to take the weight and keep the network alive.
What is a Node
The purpose of a node is to keep a copy of the network’s database. Each node is an identical replica of the database, as long as it is up-to-date and fully synced. Anyone can create, or spin-up, a node. While they’re not particularly resource-heavy in terms of computing power, they do require a substantial amount of hard drive space. Full copies of the network’s database can be hundreds of gigabytes in size, and they only ever get bigger. Any users planning on hosting a node should be prepared to handle large amounts of data.
Nodes, Kernels, and the AVM
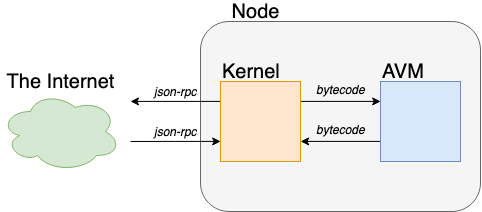
There are three different components on the Aion network: nodes, kernels, and the Aion Virtual Machine (AVM).
Nodes are essentially a container for both the kernel and the AVM. Requests coming into a node first go to the kernel, using the JSON-RPC layer. JSON-RPC stands for JavaScript Object Notation Remote Procedure Call and is an agreed-upon standard that allows different programs to interact with each other. The kernel then translates this request into bytecode, which is something that the AVM can understand. This translated-request is then passed off to the AVM that processes it and returns a response to the kernel. Finally, the kernel translates the response back into JSON-RPC and sends it out back to the user on the internet.
Multiple Kernels
The reason that Aion has two kernels is for redundancy. If a huge failure or potential bug is found within one of the kernels, that set of kernels can be taken offline while the issue is fixed. In the meantime, the remaining set of kernels of the network can take the load and keep the network alive. For example, if there was a critical bug found within the Rust, all nodes running that kernel can be taken offline. The remaining nodes on the network that are running the Java kernel can pick up the slack left by the Rust kernels. Once the Rust kernel has been fixed, the nodes running a Rust kernel are turned back online and the Java kernel releases the slack it was holding.
Mining
Both full nodes and mining nodes are similar, in that they both have a full copy of the network database. They differ in the fact that only mining nodes process any data or requests on the network. Miners are responsible for taking requests and transactions from other users on the network and adding them into the network database. This process is called proposing a block as is very computationally difficult to do. This process is essential to the network, and the blockchain cannot work without miners providing this service. As such, miners are rewarded for their services in the form of crypto-currency.
Due to the difficulty of mining, the physical computers that run the mining nodes often contain multiple high-end graphics cards, as well as other expensive pieces of hardware. This makes them fairly expensive to build and maintain.
Light Nodes
As previously mentioned, nodes contain a full copy of the network database, and as such take up a substantial amount of disk space. This can be a problem, especially when a device will limited storage (such as a mobile phone or tablet) needs to access the database. Large storage requirements also pose an issue when trying to sync a node over a slow network.
One solution to this problem is to only store a small section of the database. Instead of having every row of data, a light node can contain a much smaller set, such as all the rowers entered into the database within the last month. This can drastically reduce the storage requirements, and increases the speed at which a device can find a particular piece of data. Light nodes come with the obvious drawback that they aren’t able to access the entire historical data of the database, and as such are only applicable for certain use-cases.